
¿Qué es el SEO?
SEO es una sigla que significa search engine optimization, en español, optimización para motores de búsqueda. Esta definición corta pero técnica puede dejarte igual que estabas, así que daremos una más larga pero más clara:
El SEO hace referencia a todas las acciones que se llevan a cabo dentro y fuera de una web para que aparezca en la mejor posición posible de los resultados gratis de los buscadores. Estos resultados son tanto los que aparecen debajo de los anuncios como los que aparecen en el mapa de Google con las ubicaciones concretas de los negocios (SEO local).
¿Mejor? Paciencia, de esas “acciones” hablaremos más tarde.
Lo que sí es importante es diferenciar desde ya entre estos resultados gratis (SEO) y los resultados pagados (PPC), que corresponden a las campañas publicitarias que se hacen en Google. Vamos, el SEO es como si abres una tienda en la avenida más concurrida de la ciudad, y el PPC es, además, pagar una pancarta que la anuncia justo a la entrada de la avenida.
Vista la definición, el siguiente paso es explicar los conceptos básicos que los expertos en posicionamiento orgánico usan a diario, términos a los que echaremos mano a lo largo de todo el artículo.
Conceptos básicos del SEO
Motores de búsqueda
Los hemos mencionado en la definición técnica del SEO. Un motor de búsqueda, o buscador, es un sistema informático que recopila y almacena la información que hay en las páginas web. Así, al buscar algo en el motor, mostrará los resultados que mejor dan respuesta a la búsqueda que has hecho.
El más usado en España y Latinoamérica es Google, pero existen otros, como Bing, Yandex, Yahoo y Baidu.
URL o “página web”
Comúnmente, se usa “página web” para llamar tanto a una página concreta como a un dominio, y no importa demasiado. Pero, cuando sí importa, lo que tenemos es un dominio formado por diferentes URL. Por ejemplo, www.dominio.com está compuesto por URL del tipo www.dominio.com/url-1, www.dominio.com/url-2, etc.
Imagínate un libro: el libro sería el dominio y cada una de las páginas de papel, una URL. Para no cargarnos de siglas, en este post usaremos indistintamente URL y página (pero sí dominio).
Rastreadores, arañas o bots
Los rastreadores, también llamados arañas o bots, son programas informáticos que acceden y leen la información que hay en las URL, y lo hacen para clasificar esa información en un índice que luego enseñará al usuario.
Como quien tiene una librería, lee todos libros a velocidad supersónica para saber de qué tratan y los ordena en las estanterías siguiendo el criterio de los más buscados o comprados.
Sitemap y robots
El sitemap es, literalmente, el mapa del dominio. Es un archivo que sirve para facilitar la tarea de los rastreadores, mostrándoles una vista general de las páginas, alias URL, más importantes del dominio. No es obligatorio tener un sitemap, pero es más que recomendable en dominios con muchísimas URL. Pensemos en un mapa turístico: incluirá solo los lugares de mayor interés, no aquellos de los que hay que pasar de largo.
Por su parte, el robots es otro archivo que sirve para bloquear el acceso de los rastreadores a ciertas URL. ¿Qué haces cuando tienes invitados en casa y no quieres que entren a una habitación? Cerrar la puerta con llave, ¿no? Pues esto es lo mismo, cerrar con llave las URL que no quieres que vean los bots.
Indexación y seguimiento de enlaces
Estos conceptos están relacionados con el archivo robots.
Indexación se refiere al hecho de que una URL aparezca en la página de resultados del buscador. Para que esto sea posible, el rastreador debe acceder al contenido de esa página y poder hacerlo público. Por ejemplo, le das permiso al invitado para que entre en la habitación Y también se lo das para que cuente a todo el mundo lo que ha visto dentro (que no debería ser nada malo…).
También es posible darle permiso para que entre pero que no cuente nada; es decir, el rastreador analiza el contenido pero no lo indexa, no lo muestra en los resultados. Este caso, aunque es menos común, es necesario aplicarlo a veces, sobre todo para las URL de contenido legal/administrativo: cookies, privacidad, envíos, devoluciones, etc.
Ahora, un enlace es una puerta que comunica dos habitaciones, dos páginas. Podemos impedir que el rastreador detecte esa puerta; que la abra, pase y la deje abierta, y que la abra, pase y la cierre.
Presupuesto de rastreo
Como las personas, los rastreadores tienen poca paciencia, y no siempre tendrán tiempo de visitar todas las habitaciones de la casa, ni siquiera cuando tengan nuestro permiso. El presupuesto de rastreo es el tiempo que un rastreador dedica a escanear el contenido de una página, por lo que debemos facilitarle las cosas y eliminar todas las trabas que pueda encontrarse por el camino.
Tiempo de carga
En el posicionamiento orgánico, ser el más rápido no siempre te asegura llegar en primera posición, pero es una de las mejores cualidades de un dominio (entre tantas otras). En el caso de Google, lo recomendable es que el dominio no tarde más de 2-3 segundos en mostrar el primer contenido al usuario.
Palabras clave e intención de búsqueda
Las palabras clave, AKA keywords en una agencia de SEO, son los términos que el usuario introduce en la barra del buscador, y puede tratarse de una sola palabra o de una oración entera con su sujeto y su predicado (muy usado para post de blog, como “Qué es el SEO y cómo funciona”).
Por ejemplo, tenemos un concesionario de coches de segunda mano que queremos posicionar en Google. Deberemos trabajar la palabra clave “coches segunda mano” colocándola en lugares muy concretos de nuestra página de inicio o de catálogo: en el título, en la descripción, en el nombre de los productos, etc.
La intención de búsqueda es ofrecer el contenido más afinado posible según la consulta del usuario. Retomando la palabra clave de antes, quien busca “coches segunda mano” quiere comprar un coche de segunda mano. No estará interesado en resultados que se alejen de su intención, como una página donde se venden coches de primera mano, un post sobre quién fabricó el primer coche y otros contenidos que no satisfacen su búsqueda.
Búsqueda de palabras clave o “keyword research”
La búsqueda de palabras clave, AKA keyword research, consiste en determinar las palabras clave más interesantes para el nicho en el que nos movemos.
Cada palabra clave tiene un volumen de búsquedas al mes y un nivel de dificultad, información que las agencias de posicionamiento en Google obtienen mediante herramientas informáticas específicas. El nivel de dificultad no es necesariamente proporcional al volumen de búsquedas, pero, cuanto más difícil sea la palabra clave, más esfuerzos de SEO harán falta.
Si teníamos un concesionario de coches de segunda mano, las palabras clave que nos interesan serán “coches de segunda mano”, “coches baratos”, “compraventa de coches”… pero nunca palabras clave que incluyan “moto”.
Arquitectura web
¿Imaginas entrar a un supermercado y que los productos estén desperdigados por aquí y por allá? Los lácteos mezclados con la fruta, la carne mezclada con el pescado, los cereales mezclados con artículos de belleza… Un caos.
En un dominio pasa lo mismo: el contenido debe estar ordenado siguiendo una estructura jerárquica lógica, partiendo desde un menú superior y bajando hacia las páginas que queremos indexar. Idealmente, no debería haber más de 3 clics desde que entramos por la puerta del supermercado hasta que pasamos el producto por caja.
Recuerda: la mezcla lleva al desorden, el desorden lleva al rechazo y el rechazo lleva al lado oscuro de Google, más allá de la página 10 de resultados.
Contenido duplicado y “thin content”
Al igual que no le gusta el desorden, a Google tampoco le gusta el contenido duplicado. Ojo, que por contenido duplicado se entiende un contenido tanto idéntico como similar.
El thin content no es más que contenido sin ningún valor para el usuario. Es decir, páginas vacías, con poco texto, rozando lo inservible. Si tú no las consideras útiles, Google tampoco lo hará.
Canibalizaciones
Hablamos de canibalización cuando dos o más URL compiten por la misma palabra clave, al presentar un contenido parecido. Las canibalizaciones hacen que los buscadores no sepan muy bien qué página mostrar, por lo que las muestran todas, en diferentes posiciones.
Autoridad de dominio
La autoridad de dominio (DA) es una de las métricas más importantes para el posicionamiento orgánico. Se trata de un valor de 0 a 100 que mide la popularidad, la relevancia o la importancia que tiene el dominio a ojos de Google.
En la vida real, la persona más popular, relevante o importante es quien tiene más contactos. En SEO pasa lo mismo: la autoridad de dominio se consigue a través de enlaces de otros dominios que conducen al nuestro.
Google no publica la autoridad de dominio, pero puede consultarse de manera estimada en herramientas de SEO como SemRush o Ahrefs.
De 0 a 100, ¿cuánta autoridad de dominio dirías que tiene la Wikipedia?
SEO On-page y SEO Off-page
Tal vez recuerdes que al principio del post dijimos que el presupuesto de SEO engloba las acciones que se realizan tanto dentro como fuera del dominio.
Pues bien, las acciones que se hacen dentro forman el SEO On-page, como son la creación del archivo sitemap y robots, la organización jerárquica de la información, la inserción de palabras clave y un largo etcétera de acciones tanto técnicas como de contenido.
En la otra cara de la moneda está el SEO Off-page, que son las acciones que se hacen fuera de nuestra web, como, precisamente, la colocación de enlaces en otros dominios para aumentar la reputación orgánica de nuestra web (DA).
Google Search Console
Google Search Console (GSC) es la herramienta oficial de Google donde consultar (casi) toda la información de SEO relativa a un dominio. ¿Que por qué decimos “casi”? Seamos sinceros:
Google no deja de ser una empresa y como tal quiere ganar dinero. Sin embargo, los resultados de SEO son gratuitos, Google no obtiene ningún ingreso por ellos. ¿Cuántas empresas dan todas las explicaciones cuando se trata de un servicio que ofrecen gratuitamente?…
Dicho esto, en Google Search Console podemos ver datos de rendimiento de páginas, experiencia y usabilidad, errores y advertencias, enlaces, etc. En cuanto al rendimiento, es importante conocer las siguientes métricas:
- Impresiones: número de veces que los usuarios han visto una URL en la página de resultados de Google.
- Clics: número de veces que los usuarios han hecho clic en nuestra URL.
- CTR: porcentaje que refleja el número de clics en comparación con el número de impresiones
- Posición media: la posición media de la URL en la página de resultados.
No obstante, una agencia de SEO profesional también trabaja con herramientas de SEO externas a Google donde consultar la información que GSC no ofrece, como el volumen de búsquedas y dificultad de una palabra clave, cambios de posiciones en la página de resultados, el DA estimado, etc.
Antes hemos mencionado SemRush y Ahrefs, pero hay otras como DinoRANK, Sistrix o Übersuggest. No todas valen para todo, así que hay que elegir las más adecuadas para la estrategia SEO que queremos desarrollar.
¿Cómo funciona el posicionamiento orgánico?
Algoritmo
Coca-Cola nunca hará pública la fórmula de su receta, Google tampoco hará público el funcionamiento de su algoritmo.
Ese secretismo es lógico, ya que, si todo el mundo supiera exactamente cómo funciona el SEO, no habría competencia: todas las páginas estarían en primera posición (aunque visualmente es imposible, claro). Es como si todos pudiéramos fabricar Coca-Cola en casa, y gratis.
Al igual que otros canales digitales, el SEO en Google funciona con un algoritmo que cambia constantemente, desde pequeñas actualizaciones que no tienen apenas consecuencias hasta las madres de las actualizaciones capaces de hundir un dominio en el olvido (ha pasado, pasa y seguirá pasando).
Factores más importantes
Aunque no sean todos, a base de prueba y error, los profesionales del SEO sí que han conseguido identificar con los años algunos de los factores que intervienen en el posicionamiento de una página.
Los que hay que tener presentes como si fueran los 10 mandamientos del SEO son:
- Autoridad de dominio: métrica que mide la popularidad del sitio web, obtenida a través de enlaces desde otros dominios.
- Seguridad del sitio web (protocolo SSL): protocolo de cifrado de datos que garantiza una conexión segura entre el ordenador del usuario y el servidor.
- Velocidad de carga: tiempo que pasa desde que el ordenador del usuario solicita el contenido al servidor y este se lo muestra en su navegador. El tiempo máximo recomendado es de 3 segundos.
- CTR: porcentaje de número de clics según número de impresiones. Si una página está en posición 1 pero nadie clica en ella, Google la bajará de posiciones al considerar que no es de interés.
- Usabilidad en dispositivos móviles: contenido adaptado al tamaño de las pantallas de los dispositivos móviles (legibilidad, espaciado, etc.).
- Experiencia del usuario en la página: interacción del usuario con el contenido de la página. Los vídeos suelen funcionar mejor que las imágenes.
- Contenido de valor: información relevante, útil y de profundidad para el usuario en función de su intención de búsqueda.
- Estructura interna de la página: ordenación jerárquica del contenido dentro de la misma página web (HTML).
- Tiempo de permanencia en la página: tiempo que el usuario pasa consultando el contenido de una URL. A contenido de mayor valor, mayor tiempo de permanencia.
- Porcentaje de interacción: porcentaje de usuarios que, desde una página del dominio, han llegado a otra a través de un enlace.
Se cree que el algoritmo de Google tiene en cuenta hasta 200 factores a la hora de posicionar una página. Y, aunque ningún mortal los conozca todos, Google da “pistas” sobre ellos, por lo que siempre hay que estar informado de lo que hacen desde Mountain View para analizar y corregir el impacto que los cambios algorítmicos tienen en nuestros resultados.
Consulta del usuario y resultados
Al margen de algoritmos y factores, el funcionamiento del SEO es como sigue.
Cuando la araña de un buscador accede a una URL pública, la rastrea, detecta las palabras clave, realiza una copia del contenido y lo almacena en el índice. No solo detecta el contenido de una única página, sino que, gracias a los enlaces, la araña va saltando de una página a otra, rastreándolas todas y haciéndose una idea del contenido del dominio.
Si el contenido en cuestión se puede indexar, Google lo situará en una posición determinada para cada palabra clave detectada. Según el nivel de optimización para una palabra clave, la página ocupará una posición más alta o más baja en la SERP (página donde aparecen los resultados de Google). Pongamos un ejemplo:
Tenemos una página donde hablamos sobre los beneficios de las medias compresivas trabajando la palabra clave “beneficios medias de compresión”. En este post mencionaremos qué son las medias de compresión, cuántos tipos hay, para qué se usan, cómo ponérselas y cómo cuidarlas.
Estas medias son unas prendas que se usan para mejorar la circulación por las piernas, para prevenir la hinchazón, el picor, la aparición de varices y algunas enfermedades que hacen que la sangre circule peor. Por tanto, es de esperar que en nuestro artículo aparezcan naturalmente conceptos como “piernas hinchadas”, “tobillos hinchados”, “circulación de la sangre”, “fatiga muscular”, “varices”, “enfermedades que afectan a la circulación”, etc.
Nuestra palabra clave principal es “beneficios medias de compresión”, y, si tenemos un buen contenido que explique los beneficios de usarlas, saldremos en primera posición cuando alguien la busque. Pero también ocuparemos otras posiciones (más, igual o menos altas) para las palabras clave secundarias trabajadas de manera indirecta, ya que semánticamente tienen que ver con la principal.
Cómo hacer un buen SEO
Antes de apretarse los machos para “pelearse” con el algoritmo, hay que saber que el posicionamiento orgánico es un trabajo a largo plazo. No es publicar un post en redes sociales, que le damos al botón y ahí lo tenemos, el primero en nuestro feed. En el SEO no hay botones mágicos. No es un sprint, es una carrera de fondo.
Para llegar a la meta, una estrategia de SEO se divide en tres pilares: las acciones técnicas, las acciones de contenido y las acciones de construcción de enlaces. Al requerir diferentes conocimientos y competencias, en una agencia de SEO es común que existan tres departamentos, uno para cada tipo de acción. De hecho, es la manera más óptima de trabajar.
Lo que bien empieza bien acaba, así que lo primero es hacer una auditoría SEO para saber en qué punto está la web donde vamos a trabajar. Esto nos permitirá establecer una hoja de ruta con todas las acciones por hacer calendarizadas, ya sean técnicas, de contenido, de enlaces o todas juntas.
Una vez identificados los errores y las oportunidades para SEO gracias a la auditoría, lo segundo es determinar por qué palabras clave queremos aparecer en Google. Si la web ya existía de antes, es probable que posicione algunas keywords, pero habrá que comprobar si son las correctas o no (intención de búsqueda).
Por ejemplo, si es una tienda de cosmética, habrá que trabajar palabras clave que se refieran a productos, como “cremas”, “exfoliantes”, “protectores solares”, “geles de ducha”, “acondicionadores” y otros productos que encontraríamos en una tienda de cosmética física.
En cambio, si es una agencia de marketing digital que quiere trabajar su blog, nos centraremos en palabras clave como “qué es el SEO”, “tipos de redes sociales”, “inbound marketing”, “cómo crear un blog”, “qué es un CMS”… Temas que permitan posicionarlos como referentes en el sector.
Si sabemos ya que el posicionamiento web es a largo plazo, sabemos de dónde partimos y sabemos adónde vamos… ¡Ahora sí empieza lo bueno! 🙂
SEO técnico
El SEO técnico, que forma parte del SEO On-page, abarca todas las acciones destinadas a mejorar el rastreo y la indexación de las URL. Aunque son acciones en general invisibles para el usuario, los rastreadores sí que las detectan, de ahí su importancia.
Asegurar el buen tiempo de carga
Varios aspectos influyen en la velocidad de carga de una web: el dispositivo del usuario y su velocidad de conexión (aunque actualmente menos), el tamaño de los archivos que forman la web, la ubicación del servidor y del hosting.
Tenemos que asegurarnos de que nuestra web tarda como mucho 3 segundos en cargar, ya que es uno de los principales factores que afectan al SEO. Podemos comprobar la velocidad con herramientas como GTmetrix, WebPageTest y PageSpeed Insights.
Las acciones que nos permitirán mejorar la velocidad de carga son:
- Reconsiderar la migración hacia un hosting que ofrezca prestaciones superiores.
- Usar una red de distribución de contenidos (CDN), de manera que los datos necesarios para cargar un sitio estén alojados en varios servidores. Las CDN eligen el servidor más cercano al usuario para así aumentar la velocidad de “entrega” del contenido, en vez de tenerlo todo alojado en un único servidor.
- Reducir peso a las imágenes para que no superen los 100 kb. Uno de los errores más típicos es subir las imágenes sin someterlas antes a un proceso de compresión, en muchos casos, imágenes que pesan hasta megas. Hay muchas herramientas online gratuitas que quitan peso a las imágenes sin quitarles calidad, y trabajan con los formatos más comunes, como JPG. y PNG.
- Eliminar enlaces hacia páginas con redirección. Una redirección es una puerta (enlace) que conecta una URL que ya no existe con otra que sí existe. Lo que afecta a la velocidad de carga y al presupuesto de rastreo es cuando existen puertas que van a la URL que ya no existe, ya que el rastreador tiene que hacer el “salto” a la URL válida. Es necesario eliminar todos los enlaces hacia las URL que ya no existen y ponerlos hacia las páginas correctas.
- Prioriza la carga en caché y la carga asincrónica. La memoria caché almacena datos de manera temporal, una versión precargada de la web que se entrega al usuario a mucha mayor velocidad que la versión estándar. La carga asincrónica, por su parte, permite cargar primero elementos como el texto y dejar para el final los elementos de CSS y JavaScript que más tiempo lleva cargar.
- Minificar código. A veces es frecuente que el código HTML (el lenguaje en el que está construida la web) incluya demasiados espacios en blanco o saltos de línea. Esto solo retrasa el rastreo de la araña, que debe seguir avanzando hasta encontrar la próxima parte escrita en el código.
La mayoría de webs están creadas con CMS, sistemas de gestión de contenidos que permiten crear una web sin conocimientos técnicos. Los hay predefinidos, como WordPress, Shopify o Prestashop, y también CMS hechos a medida.
Según el CMS que usemos, muchas de las acciones para mejorar la velocidad de carga pueden hacerse mediante plugins. Pero cuidado con llenar nuestro CMS de plugins, ya que el exceso de ellos también afecta a la velocidad de carga. ¿El plugin que te instaló el amigo que hacía pinitos en informática y que ya no usas para nada? Ya estás tardando en eliminarlo.
Crear el archivo sitemap.xml y el robots.txt
Sitemap.xml
El sitemap.xml es el archivo donde aparecen las principales URL del dominio. La función de este archivo es facilitar el rastreo de la web, con los consecuentes beneficios para el SEO. Aunque no es obligatorio hacer uno, es muy recomendable para dominios con muchísimas URL, como las tiendas online.
Hay diferentes maneras de crear este archivo: usar un plugin que permita generarlo (según el CMS), recurrir a una herramienta gratuita o de pago, o hacerlo manualmente mediante un editor de texto (la opción más laboriosa y menos recomendada).
El sitemap debe tener extensión XML y alojarse en la raíz del dominio: www.dominio.com/sitemap.xml. Una vez creado, hay que indicar su ruta en Google Search Console.
Es importante no confundir el sitemap.xml y el sitemap.html. El primero es específico para los rastreadores de los motores de búsquedas, mientras que el segundo, aunque ya en desuso, es un mapa que muestra al usuario las URL más importantes del dominio.
Robots.txt
El archivo robots.txt sirve para indicar a los rastreadores qué URL pueden visitar y cuáles no. De hecho, es el primer archivo que el bot buscará nada más entrar en el dominio.
Este archivo sirve para optimizar el presupuesto de rastreo, impedir el acceso a páginas duplicadas y privadas, y ocultar recursos no interesantes para SEO, como archivos de administrador, PDF, etc. Si no contamos con este archivo, cualquier rastreador podrá acceder a cualquier URL del dominio (a todas las habitaciones de nuestra casa).
El robots.txt tiene una sintaxis muy sencilla, formada por el nombre de los rastreadores (User-agent), una regla (Allow/Disallow) y las líneas con las URL permitidas o bloqueadas para ese rastreador.
Si impedimos el rastreo de una URL, el robot tampoco podrá acceder a las URL que dependan de ella. Imagina tres vagones de un tren: A-B-C. Si desenganchamos el B, el bot no podrá acceder al vagón C salvo que se lo indiquemos expresamente.
Veamos algunos ejemplos de robots.txt:
- Bloquear a todos los rastreadores el acceso a toda la web
User-agent: *
Disallow: /
En estas líneas, el (*) indica que la instrucción es para todos los rastreadores. El (Disallow: /) indica que bloqueamos todas las URL de la web. ¿Cuándo queremos impedir el rastreo de toda la web? Por ejemplo, cuando estamos haciendo modificaciones importantes en ella, aunque esta no es la mejor práctica para SEO.
- Bloquear el acceso solo a un bot
User-agent: *
Allow: /
User-agent: Googlebot
Disallow: /
Indicamos que todos los bots (*) pueden rastrear toda la web (Allow: /), pero especificamos que el de Google (Googlebot) no tiene permiso. ¿Cuándo impedir que Google rastree nuestra web? Bueno, como agencia de posicionamiento en Google, no lo aconsejamos, ya que Google es el motor de búsqueda más usado tanto en España como en Latinoamérica.
- Bloquear el acceso a páginas concretas
User-agent: *
Disallow: /página-1
Disallow: /página-2
Disallow: /página 3
En este archivo robots.txt, hemos bloqueado el acceso de todos los bots a las páginas 1, 2 y 3 de nuestra web. Podrán acceder sin problemas al resto.
- Bloquear el acceso a una página, pero permitir el acceso a las que dependen de ella
User-agent: Google-bot
Disallow: /blog
Allow: /blog/que-es-el-seo
Allow: /blog/como-hacer-seo
En este ejemplo, impedimos al bot de Google acceder a la página de nuestro blog y, por tanto, a todos los post que van “enganchados” a esa URL. Pero sí tiene permiso para acceder a esos y solo a esos dos post en concreto: “¿Qué es el SEO?” y “¿Cómo hacer SEO’”.
¿Cómo saber qué paginas bloquear en el robots.txt? Páginas de carrito, páginas de gracias, páginas de recursos de administrador o de usuario, páginas dinámicas, páginas del buscador de la web… son las URL típicas que deben bloquearse con este archivo.
Al igual que el sitemap.xml, hay plugins para crear el archivo robots.txt, aunque es relativamente fácil hacerlo en un simple editor de texto plano. CMS como WordPress y Shopify crean un archivo robots.txt por defecto bastante completo, aunque nunca estará de más que un experto en SEO técnico lo revise.
Desindexar URL de páginas legales
El robots.txt, como hemos visto, impide que los bots rastreen páginas concretas. Existe un comando HTML parecido al robots.txt, que se usa para impedir la indexación de páginas rastreadas, caso típico de las páginas con contenido legal, cookies, envíos, etc.
Este tipo de páginas deben rastrearse, pero no deben mostrarse en los resultados de búsqueda, pues no son interesantes para el usuario. Gracias al meta-robots, indicamos que el motor de búsqueda no debe incluirlas en su índice.
Este comando HTML tiene dos instrucciones: “index”, es decir, indexar la URL (por defecto), y “noindex”, no indexar esa URL aunque esté rastreada. Puede insertarse manualmente en el código fuente de la página, pero también hay plugins de SEO que permiten añadirlo en unos clics.
Seguimiento de enlaces
¿Recuerdas cuando hablábamos de la autoridad de dominio? ¿Esa especie de “fuerza SEO” que tiene una URL? Bien, ahora piensa que el dominio (la página de inicio) es un vaso y que la autoridad de dominio es el líquido que contiene.
Gracias a los enlaces, el vaso de la página de inicio vierte parte del líquido al vaso de otra URL, pasándole así un poco de su autoridad. A su vez, la segunda URL le pasará parte del líquido a otra URL hacia la que hay un enlace, y así hasta que el líquido esté bien distribuido entre todos los vasos que merece la pena llenar.
Por defecto, un enlace pasará autoridad, pero podemos impedir que eso ocurra mediante un atributo HTML: el “nofollow”. Este atributo puede hacer referencia a todos los enlaces que contiene la URL, en cuyo caso se insertará en el comando meta-robots. Sin embargo, si queremos que solo un enlace en concreto no pase autoridad a la URL hacia la que dirige, el “nofollow” se insertará en el código HTML que indica la presencia de ese enlace.
No seguir ningún enlace de la URL
Aquí, debemos insertar el atributo “nofollow” en el “meta-robots” de la URL. Teniendo en cuenta las instrucciones “index” y “noindex” de antes, las combinaciones posibles son cuatro:
- “index, follow”: se indexa y los enlaces transmiten autoridad.
- “index, nofollow”: se indexa, pero los enlaces no transmiten autoridad.
- “noindex, follow”: no se indexa, pero los enlaces transmiten autoridad.
- “noindex, nofollow”: ni se indexa ni los enlaces transmiten autoridad.
No seguir un enlace concreto de la URL
El meta-robots indicará que la URL es “follow”, y añadiremos el “nofollow” en el enlace en cuestión de la siguiente forma:
“Como explicamos en nuestro post sobre <a href=“www.dominio.com/blog/que-es-el-seo” rel=“nofollow”>qué es el SEO</a>…”
Así, nuestro post sobre “Qué es el SEO” no recibirá la autoridad de la página en la que está insertado el enlace a él.
Errores 404 y redirecciones a 301
¿Qué sientes cuando clicas en un resultado en Google y la página a la que llegas no existe? Efectivamente, una frustración que te hace cerrarla inmediatamente. Que una página no exista (error 404 en el argot técnico) es perjudicial para la experiencia de usuario y, por tanto, para el SEO.
Para saber qué URL de tu dominio dan este tipo de error, debes consultar Google Search Console, donde aparecerá un listado de ellas, y también recurrir a herramientas de rastreo que detecten los errores 404 de tu web. Cuando las detectes, debes redirigir la página 404 hacia una URL correcta y eliminar todos los enlaces que conduzcan a ella.
Las redirecciones 301, en cuanto a ellas, se hacen cuando cambiamos una URL por otra. Por ejemplo, www.dominio.com/blog/que-es-el-seo – > www.dominio.com/que-es-el-seo, donde hemos eliminado “blog” de la URL original. Es muy importante prestar atención al nombre de las URL, ya que dos URL pueden parecer idénticas al ojo humano, pero no así al ojo de los rastreadores. El más mínimo cambio en el nombre de la URL (una letra, una barra, etc.) la convierte en una URL completamente diferente, con las implicaciones que eso tiene.
De cara al SEO, se trata de eliminar los enlaces que vayan a una página 301, es decir, a una página que redirija a otra, y ponerlos hacia la URL correcta, que es aquella a la que redirige el 301. El objetivo de esto es optimizar el presupuesto de rastreo, eliminando el “salto” que el rastreador debe hacer desde la URL redirigida a la URL final.
URL espejo y URL canonicals
Repetimos: el ojo del profesional en SEO sabe leer detenidamente las URL. Insistimos en esto para hablar del siguiente aspecto del SEO técnico, las URL espejo y las URL canonicals.
Las URL espejo son URL aparentemente iguales pero, en realidad, diferentes. Nos referimos a pequeñas variaciones como las barras (/) o incluso las “www”. Por ejemplo:
www.dominio.com/blog/que-es-el-seo
www.dominio.com/blog/que-es-el-seo/
O
www.dominio.com/blog/que-es-el-seo
dominio.com/blog/que-es-el-seo
Las URL espejo, como las del ejemplo, son un problema para el SEO porque crean contenido duplicado, esto es, dos URL diferentes con un contenido idéntico. Hay tres soluciones para corregirlas:
- Eliminar una de ellas y redirigirla a la correcta (lo menos recomendable).
- Aplicar un “noindex” a la URL incorrecta.
- Usar las URL canonicals
Las URL canonicals indican a los rastreadores qué URL es la correcta, la URL a la que tiene que hacer caso y, por tanto, indexar. Se trata de un atributo HTML que se inserta en la cabecera del código fuente de la URL incorrecta. Igualmente, hay que indicarla también en la URL buena (canonicals autorreferenciadas).
En el ejemplo de antes:
Si www.dominio.com/blog/que-es-el-seo es la URL incorrecta, debemos indicar al rastreador que la buena es www.dominio.com/blog/que-es-el-seo/, insertando en la cabecera de la primera el siguiente atributo: <link rel=“canonical” href= “www.dominio.com/blog/que-es-el-seo/”>. De esta manera, estamos diciendo al rastreador que ignore la URL sin (/) y solo haga caso a la URL con (/).
La buena noticia es que ya hace años que los CMS evitan por defecto las URL espejo e insertan automáticamente las canonicals. Pero, una vez más, siempre vendrá bien contar con la ayuda de un experto en SEO técnico que revise esta configuración.
“Mobile first” y usabilidad
Al igual que los CMS suelen evitar el error anterior, también adaptan el contenido al formato móvil. Ya quedaron atrás los tiempos en que existía una versión de la web para escritorio y otra para formato móvil.
No obstante, según el CMS, sí que es posible que la versión móvil tenga menos legibilidad, contenidos más anchos que la pantalla, poco espaciado entre botones que impiden el clic y otros problemas de formato que deben corregir los SEO técnicos.
Recordemos que Google prioriza la versión en móvil, por lo que este formato debe estar como oro en paño y tener la máxima usabilidad, uno de los factores que más influyen en el SEO.
SEO de contenido
Si has sobrevivido leyendo hasta aquí, ahora pasamos a una parte más divertida: el SEO de contenido.
Esta parte del SEO, que también está incluida dentro del posicionamiento orgánico On-page, es la que trabaja el contenido que habrá en las URL, un contenido enfocado a atraer a los usuarios que realizan las consultas en los motores de búsqueda.
Las personas dedicadas al SEO-content no están especializados en la parte técnica, aunque sí tienen conocimientos mínimos para realizar ciertas tareas que están a caballo entre lo técnico y el contenido.
Keyword research
El keyword research es uno de los pilares del SEO de contenidos (y del SEO en general). Como dijimos al principio de este (extenso) artículo, consiste en identificar las palabras clave por las que queremos posicionar el dominio, teniendo en cuenta el nicho, el volumen de búsquedas mensuales, la dificultad, la altura del embudo de ventas y (esto siempre se olvida) el tiempo que tengamos para ello.
Para detectar las palabras clave interesantes y obtener información sobre ellas, lo mejor es contar con herramientas como SemRush. Por un lado, esta herramienta te indica quiénes son los competidores orgánicos del dominio que queremos posicionar, así como las keywords que están trabajando. Por otro, te da sugerencias muy útiles de palabras clave basadas en la consulta inicial, entre tantísimas otras funciones y datos que ofrece (no, no vamos a comisión).
Por ejemplo, si tienes una tienda online de calzado para mujer y necesitas trabajar el SEO ecommerce, las palabras clave estrella serán “zapatos para mujer”, “stilettos”, “sandalias”, “cuñas”, “botas”, “bailarinas” y otros tipos de calzado femenino. Cada una de esas keywords deberá trabajarse en diferentes URL, a priori, “zapatos para mujer” en la página de inicio y las demás en páginas de colección o catálogo.
La cosa no termina ahí, pues, según los productos que haya, es probable que tengamos que asignar una palabra clave a cada uno de ellos, como “stilettos rojos”, “cuñas doradas”, “botas negras”, “bailarinas de leopardo”, dependiendo de las características que encajen con la keyword (intención de búsqueda).
Una vez identificadas las keywords que queremos trabajar, pasamos a la siguiente fase: la arquitectura de la información.
Arquitectura de la información
La arquitectura de la información es la manera en que presentamos los contenidos de la web. Tener una buena arquitectura facilita la navegación al usuario y a los rastreadores, quienes irán accediendo a las diferentes URL a través de los enlaces que hay entre ellas.
Para implementar una arquitectura de la información, o arquitectura web, hay que seguir una jerarquía lógica, donde el contenido general se irá desgranando en niveles hasta el contenido específico. Esos contenidos, que aparecerán en una página concreta, estarán centrados en una de las palabras clave que hemos seleccionado en la fase anterior. Y decimos una palabra clave (sinónimos incluidos): no es óptimo trabajar dos o más palabras clave en una misma página; lo que conseguiríamos con esto es liar a Google y al usuario.
Para el ejemplo de la tienda de calzado de mujer, una estructura lógica y sencillita sería la siguiente:
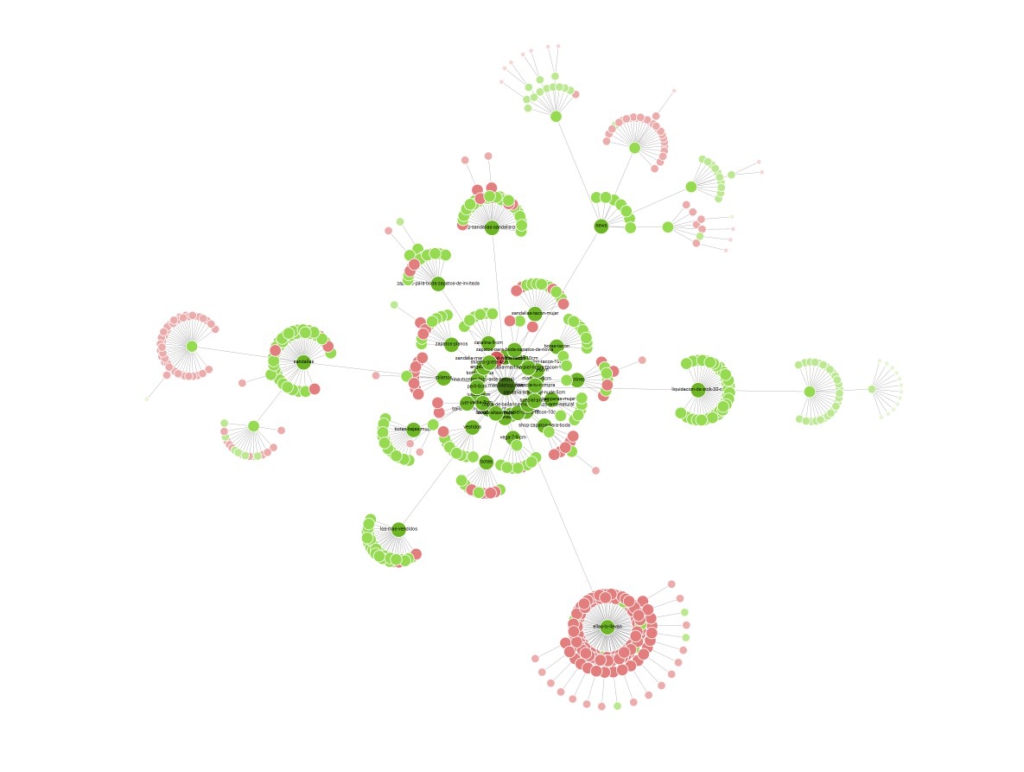
El punto situado en el centro de la imagen es la página de inicio. De ella, parten varios enlaces hasta páginas de colecciones (Sandalias, Stilettos, Cuñas, Botas, Bailarinas…). De cada colección, parten más enlaces hacia los productos que contiene.
Desde la página de inicio, también hay links que van hacia otras URL que no son colecciones ni productos. Hablamos de la típica página de Contacto y del Blog, desde la cual parten los enlaces hacia cada post.
Lo óptimo para un buen posicionamiento orgánico es que no haya más de tres clics desde la página de inicio hasta llegar a un producto o a un post del blog. Esto es lo que los expertos en SEO llaman “profundidad”, por lo que hay que ponérselo fácil al usuario y al rastreador para que puedan hacer pie y no se ahoguen en una estructura muy profunda e incomprensible.
Asignación de palabras clave a cada URL
Sabiendo las palabras clave que vamos a trabajar y la estructura de contenido, ahora debemos colocar la keyword concreta en la URL concreta. Pero ¿en qué lugares de la URL debemos incluirla? Sobre todo en:
- URL: la propia URL debe contener la palabra clave. Esto hace, además, que su sintaxis sea amigable, es decir, sin cosas tipo “www.dominio.com/UJFkid_8l2k”. Si es la página de las sandalias, por ejemplo, la URL amigable sería “www.dominio.com/sandalias-mujer”.
- Título SEO: el título SEO es la primera frase que aparece en la página de resultados de los buscadores. En el caso de Google, no debe tener más de 55 caracteres, aunque en realidad el espacio disponible se mide en píxeles: una “i” ocupará menos que una “m” a pesar de que las dos son un caracter.
- Metadescripción: es la descripción que aparece debajo del título SEO. En su caso, no debe superar los 155 caracteres, pero, una vez más, debemos tener más en cuenta los píxeles a la hora de fijar la longitud ideal. No es un factor de posicionamiento orgánico, pero sí incita al usuario a hacer clic.
- Menús: los botones de los menús deben contar con la palabra clave principal, o al menos parte de ella. Por ejemplo, cuando hiciéramos clic en nuestro botón de “Tienda” del menú superior, se desplegarían elementos llamados “Stilettos”, “Sandalias”, “Chanclas”, pero sin “de mujer”.
- Encabezado H1: el H1 es el título de la página, el encabezado que verá el usuario una vez dentro de la página. Lo ideal es que tenga menos de 60 caracteres, y no puede ser exactamente igual que el título SEO.
- Texto de la página: la palabra clave también debe aparecer en el texto de la página. “Texto” no es solo los párrafos, también lo es, por ejemplo, el nombre de los productos. No existe un número mínimo ni máximo de veces que debe aparecer la palabra clave en el texto; el mejor consejo es que se use de manera natural, sin introducirla forzosamente. Hacerlo en exceso es perjudicial para el posicionamiento de la página.
Estructura de encabezados
El H1 no es el único encabezado que debe aparecer en la página. Hay más encabezados, o subtítulos, hasta seis, que sirven para estructurar el contenido de la página.
Así, la página tendrá un título H1 que identifica su contenido, la palabra clave principal. El contenido se dividirá en encabezados H2 con sinónimos de la palabra clave principal, y estos dentro tendrán encabezados H3, que incluirán conceptos semánticamente relacionados con la palabra clave principal. Google no tiene muy en cuenta a partir del cuarto encabezado, el H4, por no hablar del H5 y el H6. Pero, si necesitas usarlos para estructurar aún más el contenido, ningún problema en ello.
Por ejemplo, la estructura de encabezados de este mismo post es:
(H1) El SEO: definición, funcionamiento y cómo aplicarlo
(H2) ¿Qué es el SEO?
(H2) Conceptos básicos del SEO
(H3) Motores de búsqueda
(H3) URL o “página web”
…
(H2) ¿Cómo funciona el SEO?
(H3) Algoritmo
(H3) Factores más importantes
(H3) Consulta del usuario y resultados
(H2) Cómo hacer un buen SEO
…
Gracias a los encabezados Hx, el contenido de la página queda dividido en secciones temáticas (de las genéricas hacia las concretas), con lo que Google y el usuario pueden comprenderlo mejor. Sin los encabezados Hx, lo que tendríamos es un bloque de texto donde la información aparecería toda seguida, sin tener claro dónde se pasa de un subtema a otro.
Imagina que te presentamos estas 6000 palabras que llevamos hasta ahora sin encabezados. ¿Te leerías semejante tocho o directamente cerrarías la ventana? Ahí le has dado.
SEO linkbuilding
El linkbuilding, como dijimos en un encabezado mucho más arriba, forma parte del SEO Off-page, y consiste en conseguir que otros sitios web pongan enlaces al tuyo, lo que se traduce en una transferencia de autoridad y relevancia. Si la web fuera un restaurante físico y cada enlace externo fuese una recomendación de un crítico gastronómico, la popularidad del restaurante crecería, ¿verdad?
Pero no todos los enlaces son iguales. Un enlace desde un sitio con alta autoridad de dominio (DA), como un periódico reconocido, vale mucho más que uno de un blog poco conocido. Además, es importante que estos enlaces sean naturales y relevantes, es decir, deben venir de sitios que tengan relación con tu temática. Conseguir enlaces de forma artificial o de sitios de baja calidad es penalizado por Google, así que hay que enfocarse en calidad más que en cantidad.
En cuanto a las técnicas más extendidas y aceptadas de linkbuilding, podemos hablar de las siguientes:
Creación de contenido de calidad
Cuando un contenido de una web te gusta, ¿eres de quienes suelen compartirlo? Si lo has hecho, ¡estabas haciendo linkbuilding sin saberlo! El contenido que más enlaces naturales genera es el informativo, útil y perenne, es decir, un contenido que siempre es relevante por mucho tiempo que pase (por ejemplo, la biografía de un personaje famoso).
Colaboraciones con bloggers
Otra buena técnica de linkbuilding es contar con el apoyo de bloggers que pertenezcan a tu nicho. Si el contenido de tu web aporta valor a su audiencia, podrían enlazarlo desde sus propios sitios.
Esta colaboración puede ser gratuita (la más recomendable), pero otras veces es probable que te pidan remuneración, por lo que no se trataría de un enlace tan natural.
Publicaciones de invitado
También llamado guest blogging, consiste en que tú mismo escribas un post en una web que no es la tuya (de ahí lo de “invitado”) y coloques un enlace hacia ella. Así, si el DA de la web que te “invita” es alto, que es lo ideal, le transmitirá autoridad a la página de tu dominio que hayas enlazado.
Esta técnica, además, también sirve para llegar a una nueva audiencia, es decir, para generar visibilidad a través de una web externa relevante para tu nicho.
Ventajas y desventajas del SEO
Como todo en la vida, el posicionamiento orgánico también te da una de cal y otra de arena, así que ahora hablaremos de las ventajas y desventajas del SEO.
Ventajas del SEO
- Tráfico orgánico a largo plazo: una vez que tu sitio web está bien posicionado, recibirás un flujo constante de tráfico sin necesidad de pagar directamente por él, como ocurre en PPC.
- Credibilidad y confianza: los usuarios tienden a confiar más en los resultados orgánicos que en los anuncios pagados.
- Mejor retorno de inversión (ROI): aunque el SEO requiere tiempo y esfuerzo, a largo plazo suele ofrecer un ROI más alto en comparación con otras formas de marketing digital.
Desventajas del SEO
- Trabajo de largo recorrido: el SEO no ofrece resultados inmediatos. Puede llevar semanas o meses hasta ver los primeros resultados concluyentes, como aumento del número de palabras clave, mejora en su posición, etc.
- Constantes cambios en los algoritmos: como todos los canales de marketing digital, el SEO depende de algoritmos que cambian constantemente y pueden hacerte caer de posiciones en solo un día. Por ello, siempre hay que mantenerse actualizado, para evitar estas situaciones.
Black Hat SEO: lo que nunca deberías hacer
La primera desventaja que antes hemos mencionado, el trabajo a largo plazo, lleva a algunos profesionales o agencias expertas en SEO a hacer lo que jamás debería hacerse: engañar a Google o, en palabras técnicas, hacer Black Hat. ¿Pero qué es el Black Hat SEO?
Básicamente, el Black Hat SEO son todas aquellas prácticas que se llevan a cabo para obtener un mejor posicionamiento de manera poco ética; es decir, acciones que intentan engañar a los algoritmos para escalar puestos rápidamente.
Sin embargo, el Black Hat SEO es pan para hoy y mucha hambre para mañana, ya que los algoritmos terminarán descubriéndolo y penalizando a esa web, bien una URL en concreto o todo el dominio.
Las penalizaciones por Black Hat, de hecho, pueden ir más allá de la bajada de posiciones: pueden llegar a la eliminación de todo el dominio en las páginas de resultados.
No vamos a dejarte con la miel en los labios, pues como expertos en SEO sabemos cuáles son estas malas prácticas que NUNCA aplicamos: saturación de palabras clave en la página, contenido oculto, páginas clonadas (una versión para los rastreadores y otra para los usuarios), páginas parásito, páginas embudo o compra de backlinks (enlaces externos que apuntan a tu dominio) son las técnicas de Black Hat SEO más conocidas.
Ahora ya lo sabes: si algún experto en posicionamiento web te propone recurrir a alguna de estas técnicas, huye y no mires atrás. A la larga, saldrás ganando. Y mucho.
Diferencias entre posicionamiento orgánico y de pago
Ahora que estamos llegando (por fin) al final de este artículo, retomamos lo que dijimos al principio de todo.
El SEO, como ya sabes a estas alturas, son las acciones para aparecer en los resultados naturales de los buscadores, es decir, gratuitos. Por su parte, el PPC es el posicionamiento de pago, o sea, las posiciones que se consiguen pagando a los buscadores.
¿Si es mejor el PPC o el SEO para tu negocio?
Por los casi 10 años que ya llevamos en nuestra agencia de marketing digital, tenemos claro que el PPC y el SEO pueden y deben ir de la mano. Una estrategia que solo se base en uno de ellos no es óptima, ya que el PPC y el SEO se retroalimentan:
- El equipo de PPC no suele ocuparse de los errores técnicos de una web, errores que no ve el usuario, pero sí las arañas de los buscadores. Es el equipo de SEO técnico quien los resuelve, y esto beneficia tanto a tus resultados de pago como a los orgánicos.
- Con PPC y SEO aumentarás tu visibilidad, ya que ocuparás más de una posición en la página de resultados: el usuario verá primero tu resultado de pago y, más abajo, tu resultado orgánico.
- Algunos usuarios nunca hacen clic en un anuncio, pero esos mismos usuarios siempre hacen clic en resultados orgánicos…
El trabajo de las agencias de SEO
Las agencias expertas en SEO te ofrecen todos los servicios para posicionar tu web en Google y otros buscadores, como la investigación de palabras clave, la optimización On-page y Off-page, y las estrategias de linkbuilding, todo en función del presupuesto SEO que se determine. Sin embargo, muchas agencias solo se dedican a recomendar, es decir, no implementan las acciones que proponen, dejando a los clientes con las mil dudas que pueden surgirles…
En Maktagg trabajamos diferente, ya que no solo elaboramos esas estrategias: también las aplicamos.
¿Tienes una web y solo la encuentran buscando tu marca?
¿Quieres ganar visibilidad sin depender de la publicidad?
¿Buscas una agencia que te garantice resultados en Google sin hacer Black Hat?
¡Cuéntanos cómo podemos ayudarte!






